

Data Pipeline in AI: The Hidden Engine Behind Intelligent Systems
From Ingestion to Inference: How Data Pipelines Drive Every AI Breakthrough
Search for a command to run...
From Ingestion to Inference: How Data Pipelines Drive Every AI Breakthrough
No comments yet. Be the first to comment.
How Autonomous AI Agents Are Designing, Building, Testing, and Evolving Mobile Apps in 2026

Architecture, Guardrails, and Engineering Trade-offs
Agentic workflows are replacing chatbots. Learn how to design, build, and ship production-ready AI agents in Python before 2026.

From simple prompts to autonomous, tool-using agents with C# and .NET

How autonomous, goal-driven AI systems are redefining productivity, innovation, and the future of intelligent work.

Artificial Intelligence (AI) gets all the glory — dazzling us with images, text, predictions, and recommendations.
But behind every intelligent output lies an unsung hero: the data pipeline.
This pipeline silently collects, cleans, and delivers the data that fuels AI systems. Without it, even the most powerful model is like a race car without fuel — all potential, no performance.
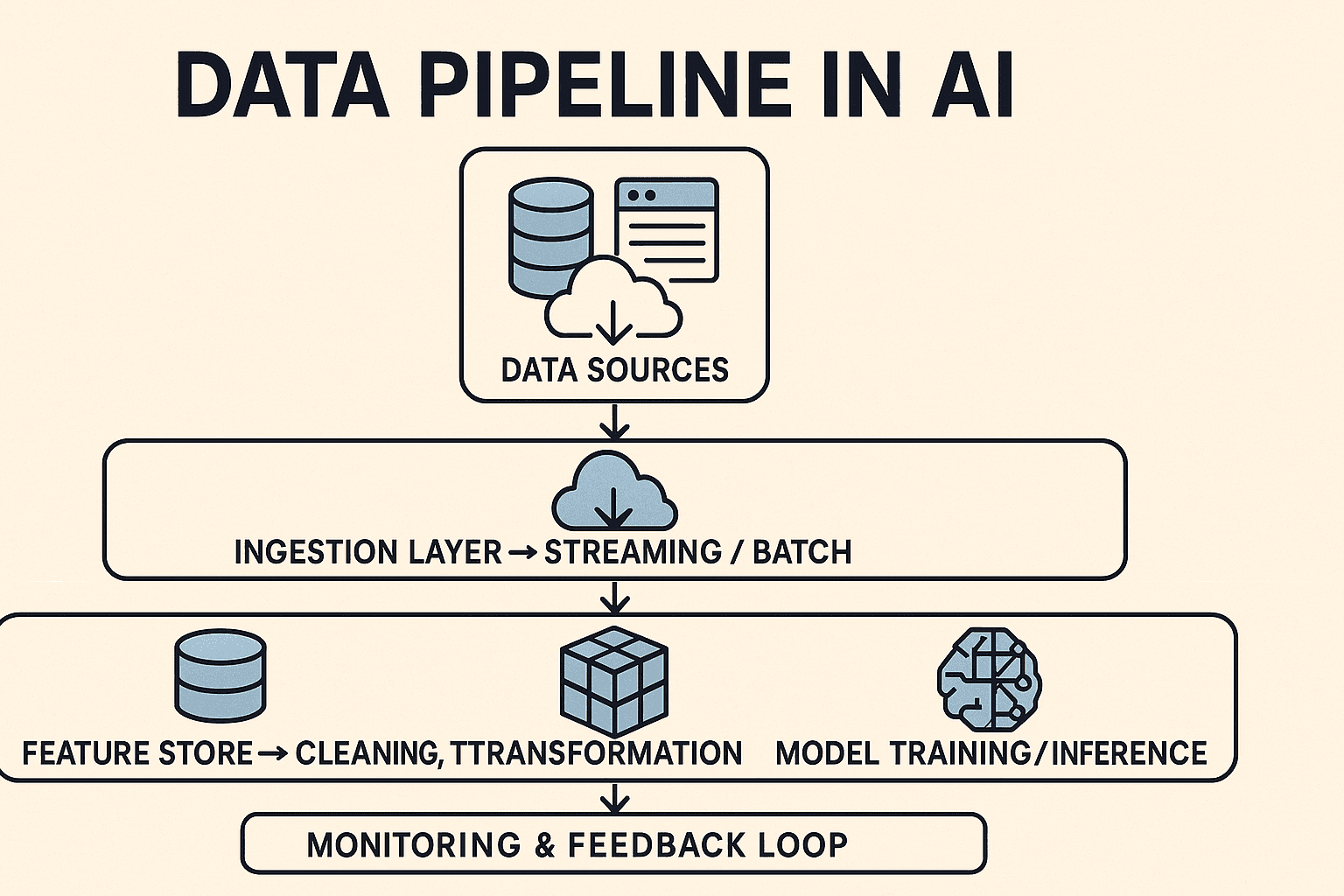
A data pipeline is the system that moves, transforms, and prepares data from its source to where AI models can use it.
Think of it as the bloodstream of AI — constantly flowing with fresh, structured, and reliable information.
In essence, it ensures that:
Raw data from various sources is collected.
It’s cleaned and transformed into usable form.
It’s stored and delivered efficiently for model training or real-time inference.
The journey begins with data collection — from APIs, databases, sensors, user logs, or streaming feeds.
Here, speed and reliability matter most.
Popular Tools: Apache Kafka, AWS Kinesis, Google Pub/Sub, Apache NiFi.
A strong ingestion layer ensures continuous, lossless flow of raw information.
Once collected, data needs a reliable home.
Data Lakes: For raw, unstructured data — AWS S3, Azure Data Lake.
Data Warehouses: For structured, query-ready data — BigQuery, Snowflake, Redshift.
Vector Databases: For embeddings in AI/NLP — Pinecone, FAISS, Milvus.
Storage isn’t just about holding data — it’s about ensuring scalability, accessibility, and governance.
Raw data rarely fits model requirements.
This stage focuses on cleaning, normalization, and feature engineering to make data model-ready.
Tasks include:
Handling missing values
Normalizing formats
Removing duplicates
Creating derived features
Common Tools: Apache Spark, Databricks, Airflow, Pandas, DBT.
Data processing defines data quality — and data quality defines AI accuracy.
For supervised learning, labeled data is essential. Models learn by example — and examples need labels.
Labeling can be:
Manual: Human experts annotate text, images, or audio.
Automated: Using pre-trained models or rule-based systems.
Platforms: Labelbox, Scale AI, Amazon SageMaker Ground Truth.
Without high-quality labels, your model learns the wrong lessons.
Pipelines aren’t “set it and forget it.”
Data can drift — sources change, formats evolve, and errors creep in silently.
Monitoring helps maintain trust and accuracy:
Schema checks
Anomaly detection
Data drift alerts
Tools: Great Expectations, Monte Carlo, Soda Core.
Continuous monitoring keeps your AI aligned with reality.
Finally, cleaned and validated data flows to its consumers:
Training pipelines for machine learning models.
Real-time inference systems like chatbots or recommendation engines.
Speed and consistency are key — milliseconds can define success.
A well-designed pipeline is the foundation of trustworthy AI.
Benefits include:
✅ Data Quality: Accurate, consistent inputs produce reliable outputs.
⚡ Automation: Enables continuous data flow and real-time insights.
📈 Scalability: Handles growing volumes efficiently.
🔐 Governance: Meets security and compliance standards.
💰 Cost-Efficiency: Reduces redundant processing and rework.
The smarter your pipeline, the smarter your AI.
Imagine a global e-commerce company:
Collects user clicks, purchases, and search logs (Ingestion).
Stores them in AWS S3 and Snowflake (Storage).
Uses Spark for cleaning and Airflow for orchestration (Processing).
Labels customers by preference type (Labeling).
Feeds that data into a recommendation engine (Delivery).
The result?
Hyper-personalized suggestions appear on your screen in seconds — powered by a smooth, real-time data pipeline.
Tomorrow’s data pipelines will manage themselves.
Expect:
AI-driven monitoring that predicts failures or drift before they occur.
Serverless data orchestration for reduced engineering overhead.
Synthetic data pipelines for privacy-safe training in regulated industries.
We’re moving toward self-healing, self-optimizing pipelines — where AI manages AI.
Machine learning models get the fame, but data pipelines are the real backbone of AI.
They ensure that data — the true fuel of intelligence — flows smoothly, securely, and intelligently from source to model.
In the world of AI, you don’t just train models — you train data pipelines.
Because when data flows flawlessly, intelligence follows naturally.