

Multimodal & Vertical AI: Beyond Text — The Next Frontier of Intelligence
How multimodal and industry-specific AI are redefining intelligence through sight, sound, and context.

Search for a command to run...
How multimodal and industry-specific AI are redefining intelligence through sight, sound, and context.
No comments yet. Be the first to comment.
How Autonomous AI Agents Are Designing, Building, Testing, and Evolving Mobile Apps in 2026

Architecture, Guardrails, and Engineering Trade-offs
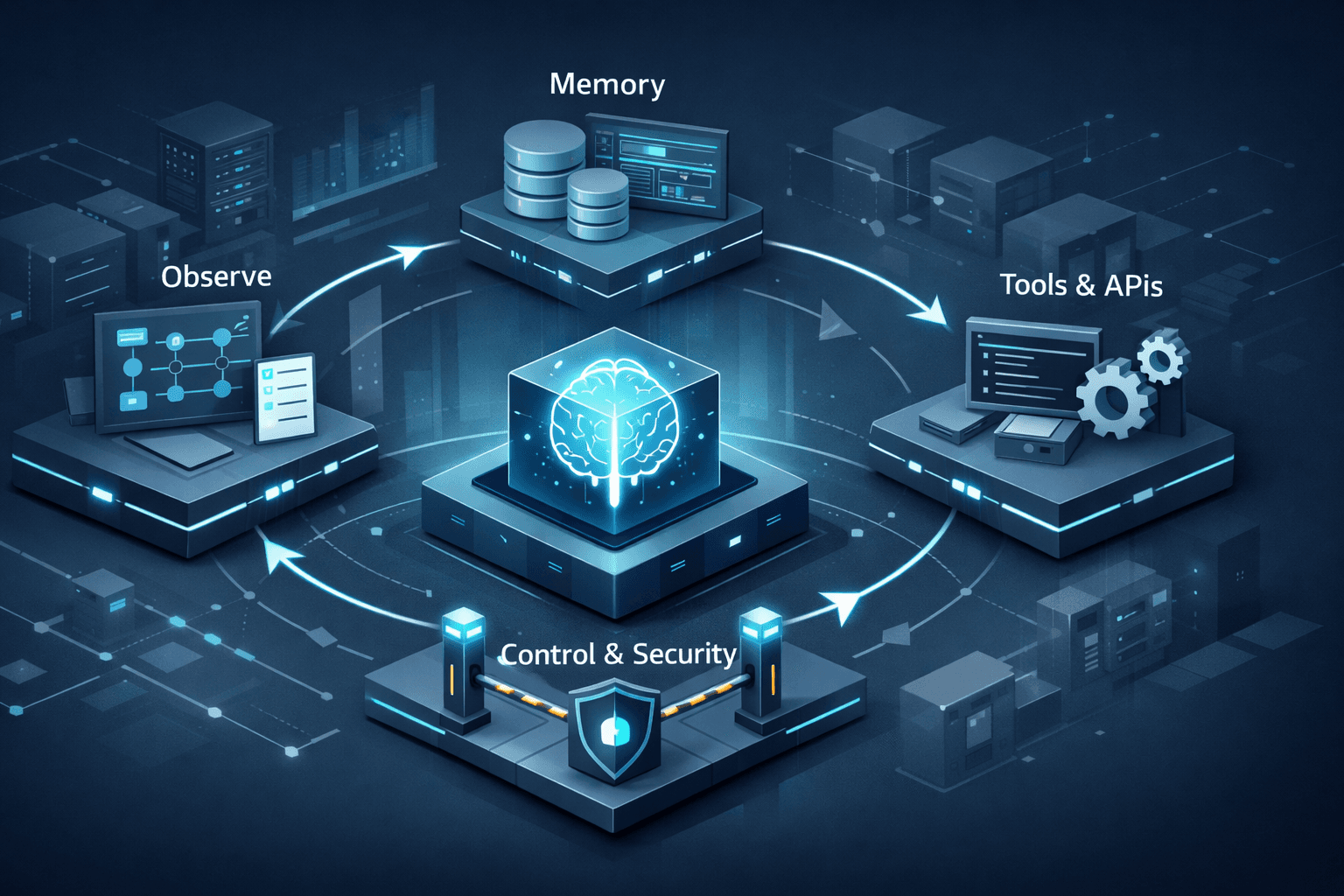
Agentic workflows are replacing chatbots. Learn how to design, build, and ship production-ready AI agents in Python before 2026.

From simple prompts to autonomous, tool-using agents with C# and .NET

How autonomous, goal-driven AI systems are redefining productivity, innovation, and the future of intelligent work.

For years, artificial intelligence (AI) systems could only read and write. They analyzed words, generated content, and mimicked human dialogue — but only within the confines of language. That era is ending. The next generation of AI doesn’t just process text; it sees, hears, and understands the world through multiple senses.
This transformation is powered by multimodal AI, a new class of systems that integrate text, vision, audio, and other sensory data. Combined with vertical AI, which tailors intelligence to specific industries and domains, these technologies are redefining how organizations innovate and operate.
Together, multimodal and vertical AI represent the next frontier in intelligent computing — one that feels more human, contextual, and adaptive than ever before.
Traditional large language models (LLMs) like GPT-3 revolutionized text-based communication, but they were inherently limited to one modality. Humans, by contrast, perceive the world through multiple interconnected senses — and so should intelligent machines.
Multimodal AI breaks this boundary. These systems combine data from different inputs — such as text, images, audio, and even sensor readings — to form a unified understanding of context.
Today’s most advanced systems — including OpenAI’s GPT-4o, Google’s Gemini 1.5 Pro, Anthropic’s Claude 3 Opus, and Meta’s Chameleon — can interpret and generate information across modalities. They can:
Describe and analyze images.
Transcribe and understand spoken language.
Extract meaning from videos or complex documents.
Blend visual, linguistic, and auditory cues into cohesive reasoning.
In practical terms, this means an AI can:
Review a product image, analyze a customer’s feedback email, and respond with both empathy and insight.
Interpret handwritten notes alongside voice memos to summarize meeting discussions.
Assist designers, engineers, or educators by integrating multiple forms of input simultaneously.
This convergence marks a shift from language-based AI to context-based AI, where systems begin to understand the world more like humans do — holistically and perceptively.
While multimodal AI expands how machines perceive data, vertical AI defines where they’re applied. Instead of broad, general-purpose models, vertical AI focuses on deep specialization — delivering intelligence tuned for specific industries or domains.
Healthcare: Models trained on radiology images, clinical notes, and patient histories assist in early diagnosis and personalized treatment planning.
Finance: AI systems integrate numerical data, text reports, and voice interactions to detect fraud, evaluate risk, and automate compliance.
Retail: Visual search tools let customers upload a photo and instantly find matching products across online catalogs.
Manufacturing: Predictive maintenance solutions combine sensor data and maintenance logs to prevent equipment downtime.
Gaming & Entertainment: AI generates storylines, environments, and characters that blend narrative and visual intelligence.
By aligning multimodal capability with industry specialization, vertical AI delivers practical, business-ready intelligence that traditional general-purpose models can’t match.
The convergence of these two paradigms is transformative across industries.
Multiple modalities reduce bias and enhance comprehension. A multimodal system can validate information from text, images, and speech, resulting in more reliable outputs.
Tasks that once required human interpretation — reviewing forms, analyzing scanned documents, processing audio feedback — can now be automated end-to-end.
With voice, vision, and gesture input, interactions become intuitive and human-centric. AI can “see what you see” and “hear what you hear,” responding in context.
Multimodal interfaces open technology to users with disabilities — through voice recognition, visual cues, or adaptive response modes.
Organizations leveraging vertical multimodal AI gain a competitive edge — blending domain knowledge with perceptual intelligence for smarter, faster decision-making.
Despite its promise, multimodal AI faces critical challenges that must be addressed for widespread adoption.
Data Fusion Complexity: Aligning text, image, and audio streams into coherent representations is technically demanding.
Resource Intensity: Training and deploying multimodal models require significant computational power and storage.
Data Privacy & Regulation: Handling visual and voice data introduces compliance risks, especially in regulated industries.
Explainability: Understanding why a multimodal model reached a conclusion remains a key research area.
According to a 2025 Gartner report, over 60% of enterprise AI deployments will include multimodal features by 2027, up from less than 10% in 2023 — signaling rapid enterprise adoption alongside rising ethical and operational questions.
In the coming years, we can expect the multimodal and vertical AI landscape to evolve in four major directions:
AI Copilots with Context Awareness:
Assistive agents that analyze on-screen content, interpret voice tone, and understand gestures simultaneously.
Immersive AI in AR/VR:
Integration of multimodal understanding within extended reality environments for real-time guidance and collaboration.
Edge and Embedded AI:
Lightweight multimodal systems operating on devices, vehicles, and IoT sensors to enable real-time decision-making.
Open-Source Acceleration:
Frameworks like LLaVA, Kosmos, and Chameleon are lowering entry barriers, enabling startups and researchers to build specialized multimodal systems without massive infrastructure.
The result will be an ecosystem of AI agents that can collaborate, interpret, and act autonomously across industries — blending sensory data with domain expertise.
Multimodal and vertical AI represent the next great leap in the evolution of artificial intelligence — from models that understand language to systems that understand the world.
They mark a turning point in how humans and machines interact: one defined by perception, reasoning, and collaboration rather than mere computation.
As these technologies mature, they will redefine industries, reshape creativity, and elevate accessibility — ultimately bridging the gap between human intuition and digital intelligence.
The AI of tomorrow won’t just read our words — it will see, hear, and understand our world.